Apache Spark 101
Share via

Give Your School The Lead Advantage
We at LEAD, focus on being a customer-centric organization. When it comes to valuing customers, it’s vital to know the potential customer. For the same, we regularly collect usage-related insights in order to analyze various areas of customer requirements. Data from multiple data stores such as postgres, mongo, s3 etc. is retrieved using Apache Drill; however, being the primary component, Drill does not completely support schema changes. Apache Spark, a prominent big data processing tool, comes into the equation to solve this problem and extract the most value from any data.
Apache drill is perhaps the most basic in the picture, while Apache spark is a generic computation engine that supports a subset of SQL queries and uses SQL-like queries to gather the data it needs to conduct those computations. It also includes drivers for a variety of storage services that can be used to run queries. Let’s glance at Apache Spark, why it is used & how it helps in providing valuable insights in order to fulfill customer requirements.
Apache Spark: a general-purpose distributed data processing engine that imports large amounts of data, performs calculations on it in a distributed environment, and then stores it for future processing to meet business requirements.

The Why & How Of Spark?
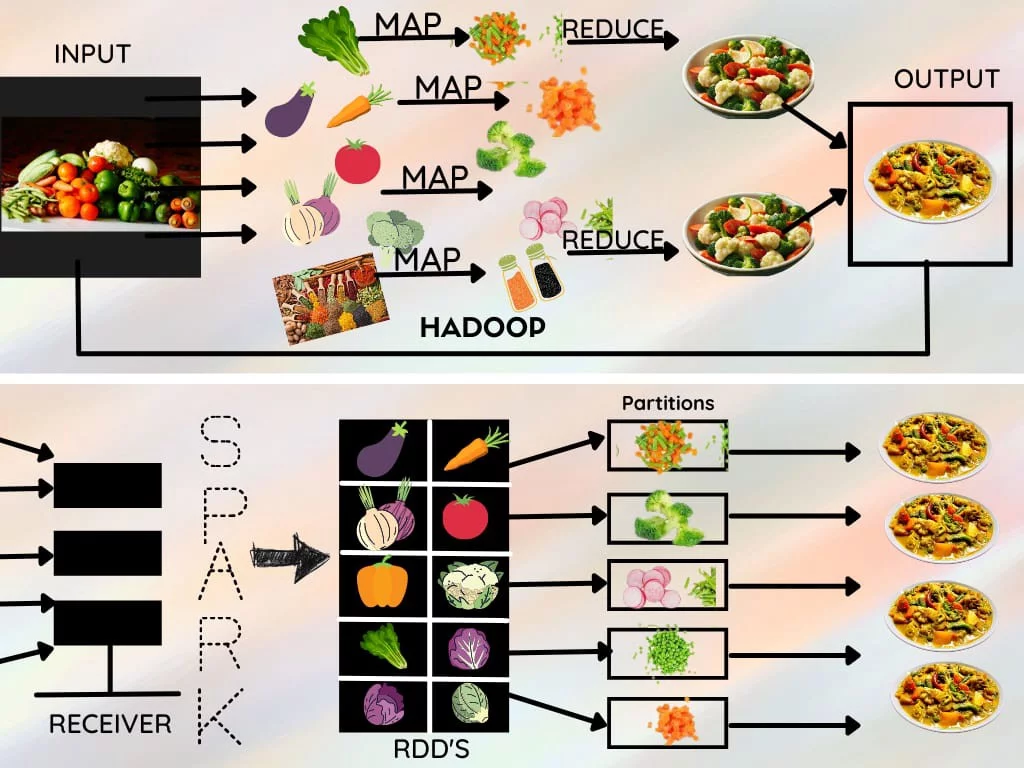
Hadoop is widely used in industries to examine large data volumes. The reason for this is that the Hadoop framework is built on a basic programming paradigm (Map Reduce), which is a scalable, flexible, fault-tolerant, and cost-effective computing solution. The major goal here is to maintain speed in processing massive datasets in terms of query response time and program execution time.
Apache Spark is a Hadoop Map Reduce based framework that extends the Map Reduce concept to allow for other sorts of computations, such as interactive queries and stream processing. The most appealing feature of Apache Spark is its compatibility with Hadoop. As a result, this is an incredibly potent combination of technologies. Using Spark and Hadoop together allows us to use Spark’s processing to make use of the advantages of Hadoop’s HDFS and YARN.
Architecture
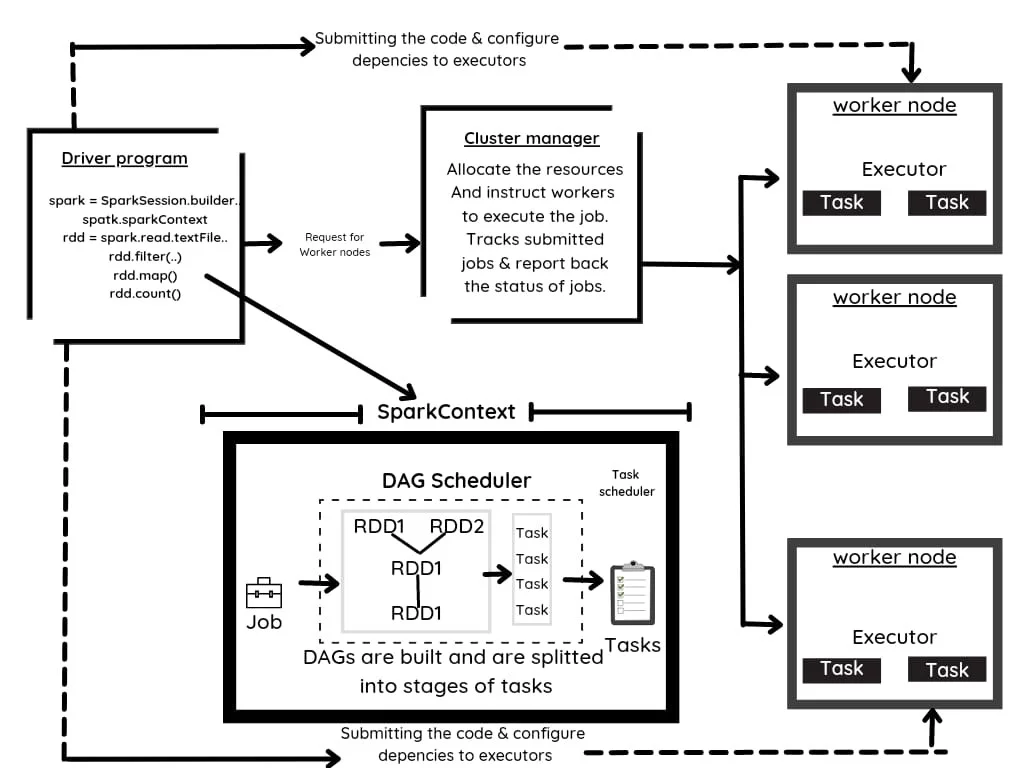
Spark may operate in a standalone cluster mode, using only the Apache Spark framework and a JVM on each server in the cluster. However, it’s more probable that you’ll want to use a more powerful resource or cluster management solution to handle your on-demand worker allocation. Apache Spark can operate on Apache Mesos, Kubernetes, and Docker Swarm.
At its most basic level, an Apache Spark application is made up of two parts: a driver that turns user code into many tasks that can be spread among worker nodes, and executors that operate on those nodes and carry out the tasks given to them. To arbitrate between the two, some sort of cluster manager is required.
Apache Spark-RDD
Spark uses a fundamental data structure known as RDD (Resilient Distributed Datasets). RDDs are distributed collections of items that are immutable, fault-tolerant, and may be acted on in parallel. They are formed by transforming existing RDDs or importing a dataset from a stable storage system such as HDFS or HBase. RDDs are divided into divisions and can be run on various cluster nodes.
Datasets are divided into two categories:
- Parallelized collections: These collections are designed to run in parallel.
- Hadoop datasets: These run operations on HDFS or other storage systems’ file record systems.
To accomplish quicker and more efficient Map Reduce processes, Apache Spark makes use of the RDD paradigm.
Job Execution In Spark
The first step is to use an interpreter to interpret the code (When you use Scala code, it is interpreted by the Scala interpreter). When the code is entered into the Spark console, Spark constructs an operator graph. The operator graph is sent to the DAG Scheduler when the action is called on Spark RDD (Direct Acyclic Graph (DAG) is a graph with finite vertices and edges. The edges indicate the operations to be done sequentially on RDDs, whereas the vertices represent RDDs. The DAG is then sent to the DAG Scheduler, which divides the graphs into stages of jobs depending on the data transformations). The operator graph is sent to the DAG Scheduler when the action is performed on Spark RDD.
The DAG Scheduler divides the operators into job phases. The stage entails performing comprehensive, step-by-step operations on the input data. After that, the operators are piped together. The stages are then handed to the Job Scheduler, which launches the task via the cluster manager, allowing it to function independently of the other stages. The task is then subsequently carried out by the worker nodes.
The process diagram below illustrates how DAG works in Spark:
Data Frames in Spark
To leverage the power of distributed processing, the concept of Data Frame comes into picture as an extension to the existing RDD API. A Data Frame in Spark is a distributed collection of data with named columns. It’s similar in principle to a table in a relational database, but with more advanced optimizations. Data Frames may be built from a variety of sources, including structured data files, Hive tables, external databases, and existing RDDs.

Spark Languages
Scala is the primary language for interfacing with the Spark Core engine, and it was used to create Spark. Spark includes API connectors for Java and Python right out of the box. Python is popular among users because it is easier and more suited to data analysis.
PySpark library can be used to execute Python applications that construct Data Frames and other similar concepts.
And That’s It!
Congratulations! You have successfully made it, now you know what spark is, its architecture, the modules it provides, job execution, how to construct a data frame, and other PySpark concepts it offers. Not to mention the fact that you’ve set yourself up to learn a lot more about Spark. There’s still a lot to learn, so stay tuned for part two, where we’ll dive deeper into Spark Streaming.
Check out other resources published by me:
- Installing Apache Spark
- Getting started with PySpark
- Try creating your first Data Frame and RDD using PySpark
- Getting started with RabbitMQ
- Introduction to Message Queuing
At LEAD, we work on technology to build excellent quality school edtech solutions to solve the problem of school education in India. Know more about us by visiting this link.


.png)

