Using ElasticSearch To Accelerate School EdTech
Share via

Give Your School The Lead Advantage
We at LEAD utilize the Elastic Stack to reveal the hidden potential of its data to gain insights about customer patterns, track performance metrics, and user analytics — all in near real-time. With countless business-critical text search and analytics use cases that utilize Elasticsearch as the backbone, we create dynamic APIs on top of it to allow easy searching. If you are new to ElasticSearch, this blog is just for you!
From Compass to ElasticSearch
So, how did Elastic co-founder Shay Bannon’s modest search engine for his wife’s cooking recipes evolve to become the most popular enterprise search engine today? Let’s start with an overview of Elasticsearch, including what it is, how it works, and how it’s used. What is an ElasticSearch?
Some people may say that ElasticSearch is “an index” or “a search engine” or “an analytics database” or a big data solution , Depending on how acquainted you are with this technology.
- ElasticSearch is a scalable search solution that provides near real-time search, and multi-tenancy support. It collects unstructured data from a variety of sources, stores and indexes it using user-defined mapping (which can also be derived automatically from data), and makes it searchable.
- Its network architecture allows it to search and analyze massive amounts of data in real time. It allows you to start small and scale up to hundreds of machines.
- Elasticsearch is frequently used to store data that must be sliced and diced, grouped by different dimensions, and so on. ElasticSearch for metrics, logs, traces etc., are examples of such analytical use cases.
Why ElasticSearch?
ElasticSearch and the “Elastic Stack” ecosystem of components have been used for an increasing range of use cases over the years, ranging from simple search on a website or document to collecting and analyzing log data, to a business intelligence tool for data analysis and visualization.

How does ElasticSearch work
Let’s go through some basic notions about how Elasticsearch organizes data and its backend components to get a better understanding of how it works.
- Document: Elasticsearch’s core and basic unit of information entity is the document, which is represented in JSON format. Documents can be archived and searched. There are one or more documents in an index, and each document has one or more fields. Each document has a distinct ID and a data type that identifies what type of object it is.
- Index: An index is a collection of documents with a common structure that is used to store and retrieve documents. An index is given a name that is used to refer to it while performing indexing, searching, updating, and deleting operations on the documents included within it.
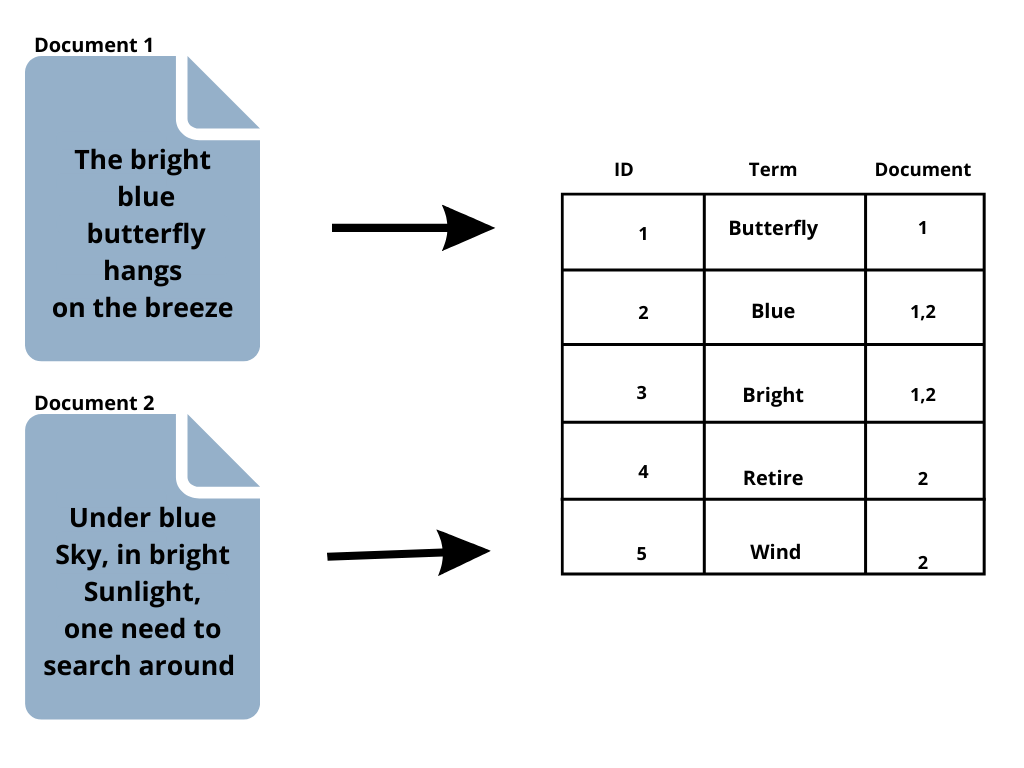
- Inverted Index: The mapping from content, such as words or numbers, to their places in a document or series of documents is stored in an Inverted Index. In short, it is a data structure that resembles a hashmap and guides you from a word to a document.
 Instead of storing strings directly, an inverted index breaks down each document into individual search phrases (i.e., each word) and then associates each search term with the documents in which it appears
Instead of storing strings directly, an inverted index breaks down each document into individual search phrases (i.e., each word) and then associates each search term with the documents in which it appears - Cluster: The distribution of tasks, such as searching and indexing, among all cluster nodes is what gives an Elasticsearch cluster its functionality. A cluster is a group of one or more computers that collectively store all of your data and enable federated indexing and search.
- Node: A single server that is a component of a cluster and stores our data as well as participating in the cluster’s indexing and search functions is called a node. Elasticsearch nodes can be set up in multiple of ways:
- Master Node : Master node manages the Elasticsearch cluster and is in charge of all cluster-wide actions like adding/removing nodes and creating/deleting an index.
- Data Node : Data node does data-related tasks, such as search and aggregation, and stores data.
- Client Node : Customer node forwards requests for the cluster to the master node and requests for data to the data nodes.
- Shards & Replicas : Elasticsearch offers the ability to break your index into numerous sections known as shards. Simply provide the desired number of shards when creating an index. Each shard functions as a complete, independent “index” in and of itself that can be hosted on any cluster node.
 Instead of storing strings directly, an inverted index breaks down each document into individual search phrases (i.e., each word) and then associates each search term with the documents in which it appears
Instead of storing strings directly, an inverted index breaks down each document into individual search phrases (i.e., each word) and then associates each search term with the documents in which it appearsReplica shards, often known as “replicas,” are copies of your index’s shards that Elasticsearch lets you create in any number. A replica shard is essentially a duplicate of a primary shard. Each primary shard in an index contains one document per shard. Replicas offer redundant copies of your data to safeguard against hardware failure and expand capacity to handle read requests like indexing and retrieval or search.
The Elastic Stack
Elastic Stack, a collection of open-source technologies for data intake, enrichment, storage, analysis, and visualization, is anchored by Elasticsearch. After its constituents Elasticsearch, Logstash, and Kibana, it is usually referred to as the “ELK” stack, which currently incorporates Beats.

Kibana
Kibana is a data management and visualization tool for Elasticsearch that offers real-time maps, pie charts, line graphs, and histograms. By starting with a single query, you may decide how to structure your data and see where the interactive visualization will take you. It can be used to explore the Elastic Stack and visualize your Elasticsearch data.
Logstash
An open-source server-side data processing pipeline called Logstash ingests data from numerous sources at once, alters it, and then transforms it into a collection. Data is collected, processed, and sent to Elasticsearch using Logstash.
For instance, Logstash enables you to connect numerous systems, such as web servers, databases, Amazon services, etc. and publish data to wherever it needs to go in a continuous streaming fashion because data is frequently dispersed across different systems in different formats.
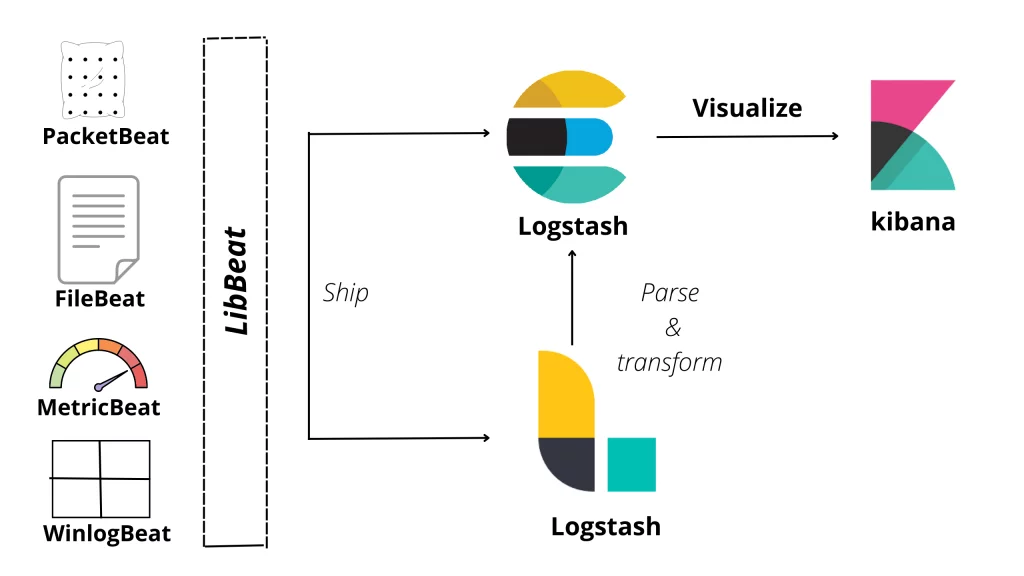
Beats
To deliver data from hundreds or thousands of computers and systems to Logstash or Elasticsearch, a group of lightweight, specialized data shipping agents called Beats is leveraged. For instance, Filebeat can be installed on your server and watch over log files as they arrive, process them, and import them into Elasticsearch in near-real time.
What are some uses of Elastic Search?
We can better grasp why and how Elasticsearch can be utilized for a variety of use cases now that we have a general understanding of what it is, the logical concepts underlying it, and its design. In the sections below, we’ll look at some of Elasticsearch’s most common use cases and give examples of how businesses are currently utilizing it.
Primary Use cases
- Application Search: for software programmes that significantly rely on search platforms to obtain, retrieve, and report data.
- Website Search: Websites which store a lot of content find Elasticsearch a very useful tool for effective and accurate searches.
- Enterprise Search: Elasticsearch is extremely beneficial for efficient and precise searches on websites that store a lot of content. It’s hardly surprising that Elasticsearch is making progress in the field of site searches.
- Logging & Log Analytics: Elasticsearch is frequently used to ingest and analyse log data in a scalable, in near-real-time.
- Security Analytics: The ELK stack may be used to examine access logs and other logs related to system security, giving you a more complete picture of what’s happening across your systems in real-time.
- Business Analytics: The ELK Stack is a great alternative as a business analytics solution because it has many built-in functionalities available. The implementation of this product, however, comes with a significant learning curve in most firms.
Summary
What precisely is Elasticsearch? We made an effort to respond to that question in this post by examining what it is, how it functions, and how it is utilized, but we have only just begun to discover everything there is to know about it. Nevertheless, based on what we’ve discussed so far, we can briefly state what an Elasticsearch is, at its core, a search engine. Its underlying architecture and components make it fast and scalable, and it sits at the centre of an ecosystem of complementary tools that, when used together, can be used for a variety of use cases, including search, analytics, and data processing and storage. If you’re interested in learning more about Elasticsearch and trying it out for yourself so stay tuned for part two, where we’ll dive deeper into ElasticSearch.
Final Words
The LEAD technology team focuses on leading edge technologies like AWS, EMR, etc., which provides you the flexibility to get involved in a multitude of areas and the window of opportunity to build your own platform. At LEAD, Data engineering deals with infrastructure and engineering aspects like how you store the data in the cloud for addressing scalability, latency and different types of data. Being a Data engineer at LEAD gets exciting when insights and algos developed are implemented and operationalized into data products and applications. There’s a thrill about automating and enabling productivity through tools and platforms at LEAD.
If you love learning new things every day, are intrigued by patterns and hidden information in data, and an avid science enthusiast, LEAD is the place for you. Check out out the recent opening we have by visiting this link or visit our website to know more about us.


.png)

